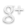


As country after country has gone into COVID-19 lockdown, we have all had to learn to communicate, network, teach, study and relate online in ways unimaginable a few short years – or even months – ago. This phenomenon is just the latest stage in the information-technology revolution and part and parcel of the ongoing development of an increasingly digital society. This revolution has touched almost every aspect of our lives, from how we work, study, shop, relax and even make and maintain personal relationships. But it is also transforming scholarship and the way we conduct and communicate academic research. Thus, it is perhaps apt, and with consummate good timing, that Oxford University Studies in the Enlightenment has chosen to subject tag our new volume as ‘History of Scholarship (Principally of Social Sciences and Humanities)’. Yet this is certainly not how we and our collaborators envisaged our project at the outset, nor can any single tag capture the content of our volume and its collaborative agenda in its entirety.
Ironically, as we write, Digitizing Enlightenment is also a living movement – or at least a loose network of scholars who meet annually in pursuit of a common agenda. That agenda was born in a series of conversations that took place from 2010, culminating in Dan Edelstein’s post-panel suggestion at the American Historical Association conference at Montreal in April 2014 that we should hold periodic meetings between like-minded digital projects relating to the Enlightenment. The aim of these meetings would be to establish common conventions and digital standards, with a view to linking our resources and realising the enormous and still largely untapped potential of Linked Open Data. Those present for Dan’s suggestion – Simon Burrows, Jeff Ravel, Sean Takats and Dan himself – have all provided chapters for our book, but much of the energy behind Digitizing Enlightenment since has come from Glenn Roe, who Simon had first encountered a month earlier in Australia, where they had both recently taken up academic positions.
t was this fortuitous coincidence, underpinned by the fertile combination of Simon’s professorial establishment funds and Glenn’s energy, together with their mutual contact books, that led to Western Sydney University hosting the first Digitizing Enlightenment symposium in July 2016. Among the projects discussed there, and in our book, were large-scale treatments of Enlightenment correspondences, theatre attendance records, and textual corpora including the mid-eighteenth century Encyclopédie; bibliometric projects were presented on the production and dissemination of literature; together with presentations on mapping and data visualization growing out of these projects. The symposium was so well received that it has been an annual event ever since. It was held at Radboud University in Nijmegen (2017), Oxford (2018), Edinburgh (2019). In 2020, but for COVID-19, it would have been held in Montpellier.
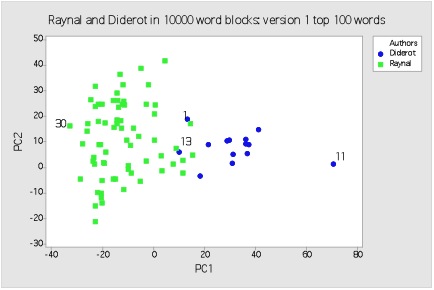
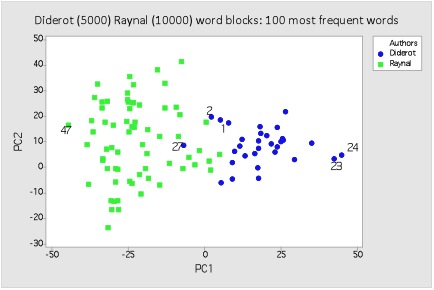
It was not entirely by chance that such a project coalesced around the guiding notion of the ‘Enlightenment’. For the long eighteenth century has been blessed by a number of high-profile and long-established digital projects. These include ground-breaking commercial datasets such as Gale-Cengage’s Eighteenth-Century Collections Online (ECCO), which features in several of our chapters, semi-commercial projects such as the Electronic Enlightenment and large academic consortiums such as the Franco-American ARTFL project. This made the Enlightenment a natural laboratory for exploring the possibilities and achievements of the Digital Humanities for transforming scholarship on a single historical era. Further, as our book emphases, our discussions built on a long tradition of digital innovation in eighteenth-century studies that can be traced back at least as far as the twin Livre et société dans la France du XVIIIe siècle volumes produced by a team led by François Furet in 1965 and 1970. It might further be added that our over-arching subject material lends itself to digital-historical analysis; the Enlightenment might after all be viewed as the long-run culmination of the intellectual turmoil and – as several contributors point out – information overload unleashed by a previous technological and communications revolution.

With this in mind, then, we offer up Digitizing Enlightenment: Digital Humanities and the Transformation of Eighteenth-Century Studies as rather more than a contribution to the history of scholarship. Certainly, we have offered a sample of Digital Humanities c. 2016-2020, as it relates to the technologies available and their application to Enlightenment studies broadly construed. In addition, the first half of the book offers detailed accounts of the origins and development of key Enlightenment digital projects up until that point, accompanied by valuable and sometimes disarming insights on the dangers and delights of digital research from foremost practitioners in the field. These chapters, as well as some later contributions, are helping to reshape some dominant meta-narratives of the Enlightenment, not least by hinting simultaneously at the enduring aristocratic leadership of the French Enlightenment and the extent to which Enlightenment literary production and consumption was infused with religious content. However, our contributors also showcase other ways that Digital Humanities scholarship is in the process of changing the field through the transparency, methodological rigour, and collaborative imperatives that are necessary concomitants of this new kind of research. Finally, the book offers a collaborative roadmap for future digital research – at a moment where, as our final contributor, Sean Takats points out, the Enlightenment is fast losing its privileged position as the most richly digitized century of the modern era. As a corollary, we hope that our volume may be as useful to scholars of other periods as for Enlightenment scholars themselves.
– Simon Burrows (Western Sydney University) and Glenn Roe (Sorbonne University)