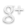A collaborative digital research project
On the heels of Cecil Courtney and Jenny Mander’s recent publication, Raynal’s ‘Histoire des deux Indes’ colonialism, networks and global exchange (OSE, 2015), I am pleased to announce a new international research project aimed at further exploring Raynal’s monumental work and its impact on Enlightenment thought. Thanks to the generous support of the Consortium for the Study of the Premodern World at the University of Minnesota, the Centre for Digital Humanities Research at the Australian National University, Stanford University Libraries, and The ARTFL Project at the University of Chicago, we have recently completed the digitization and text encoding (in TEI-XML) of the three primary editions of the Histoire philosophique et politique des établissements et du commerce des Européens dans les deux Indes. These editions – the first edition of 1770, the second of 1774, and the 1780 third edition – were those that Raynal himself oversaw during his lifetime.
Our digital editions are based on high quality PDFs provided by the BNF’s Gallica online library (1770 and 1780 editions) and the Bodleian’s Oxford Google Books Project (1774 edition). A preliminary search interface has been built using the ARTFL Project’s PhiloLogic software and can be accessed here: Raynal search form. Users can query one or all of the above editions, which represent the first publicly available full-text digital edition(s) of the Histoire des deux Indes. In the coming months we will release a new version of the database running on ARTFL’s state-of-the-art PhiloLogic4 system, along with a preliminary ‘intertextual interface’ that will aim to incorporate the text of the three separate editions into one reading interface.

Title page and frontispiece of the 1780 edition of Raynal’s Histoire des deux Indes (Gallica).
Diderot, Hornoy, and the 1780 edition
What is perhaps most exciting about these new digital resources is the inclusion of a unique 1780 edition of the Histoire des deux Indes recently made available by the BNF. Acquired at public auction in March 2015, this particular edition had been conserved since the late 18th century in the private library of Alexandre Marie Dompierre d’Hornoy (1742-1828). A lawyer at the Parlement de Paris and great-nephew of Voltaire – he in fact inherited Jean-Baptiste Pigalle’s infamous nude statue of Voltaire upon his great-uncle’s death – Hornoy corresponded with many of the philosophes, Diderot included. His copy of the Histoire contains pencil marks in the margins of some passages, an unremarkable fact, perhaps, were it not for a note written by Hornoy just above a three-page insert at the beginning of the first tome. The handwritten tables included in the insert list all the sections marked in pencil over the four volumes of text: ‘mourceaux qui sont de M. Diderot’, Hornoy writes, ‘marqués en crayon par Mme de Vandeul’. Madame de Vandeul was, of course, Diderot’s daughter.
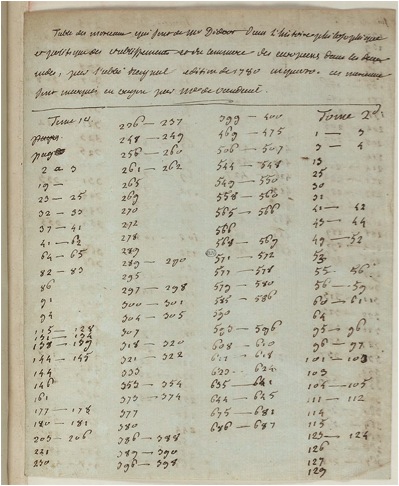
Handwritten insert of the 1780 edition (Gallica)
The existence of such an annotated volume of the Histoire was posited in the 19th century, notably by Joseph Marie Quérard in his Supercheries littéraires dévoilées (5 vols., 1845-1856). Quérard claimed that there supposedly existed a copy of the 1780 edition on which Diderot himself had marked in pencil all the passages that belonged to him [1]. According to Quérard, this copy became the property of Madame de Vandeul shortly after Diderot’s death. Whether or not the copy acquired by the BNF is the same as that owned by Vandeul we cannot say for sure, but Herbert Dieckmann, in his inventory of the ‘fonds Vandeul’, also mentions the hypothetical existence of a copy of the in-4o edition (e.g. 1780) that was purportedly annotated by hand, but that had since been lost [2].
Some preliminary experiments
While consensus as to the validity of Hornoy’s assertion that the marked sections are in fact those authored by Diderot will most likely take years to accrue, we can begin, using the new digital edition, to ask some basic questions as to the authorship claims indicated in the text. Thanks to extensive markup in TEI-XML notation, sections purportedly belonging to Diderot are clearly indicated, and perhaps more importantly, can be extracted as one test corpus. Using some basic statistical measures drawn from authorship attribution studies, or Stylometry, we can begin to think about how the ‘Diderot’ sections may, or may not, differ stylistically – i.e. in terms of comparative word usage over the most common words, an established metric of ‘authorship’ in stylometry and forensic linguistics – from the rest of the text.

Page from 1780 edition with ‘Diderot’ section marked in pencil (Gallica)
Working with the Centre for Literary and Linguistic Computing at the University of Newcastle (Australia), and in particular with their Intelligent Archive software for stylistic and statistical text analysis, we extracted the top 200 words for each ‘author’ (e.g. those drawn from sections putatively by Diderot, and the remaining ‘Raynal’ sections). As a result, we were left with 4 ‘Diderot’ tomes (containing all of the text marked in pencil) and 4 ‘Raynal’ tomes (containing the remainder), representing their unique word lists over the entire edition. For a first preliminary test, we ran a cluster analysis on the 8 tomes to see if they would cluster together or separately:
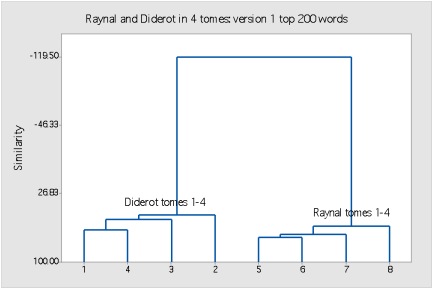
Cluster analysis of ‘Diderot’ tomes vs. ‘Raynal’ tomes, based on top 200 word lists
Cluster analysis works by separating (or clustering) the most similar texts first and the most distinct last, in this case into 2 branches. A division like the one above, clearly separated into two distinct ‘trees’ is a very clear indication that the texts in each of the two branches are highly likely to be those of two different authors.
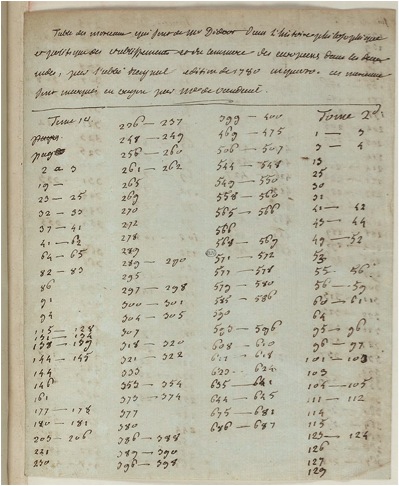
Principal component analysis (PCA) provides another method of examining our corpora. PCA is a procedure for identifying a smaller number of uncorrelated variables, called ‘principal components’, from a large set of data. The goal of PCA is to explain the maximum amount of variance with the fewest number of principal components. In our case, it is a technique that allows for the first two principal components of our two sets of texts, i.e. their word variance, to be plotted on a bi-axial or two-dimensional graph. One of these plots (using the 100 most frequent words of the full text) with both text corpora divided into 10,000 word blocks, is shown below.
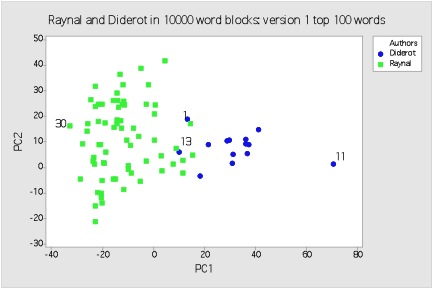
Principal component analysis using 10,000 word blocks and 100 most frequent words
The disparity in size of our two test corpora meant that while there were 68 text sections for Raynal (in green), there were only 14 for Diderot (in blue). Nonetheless, the separation between the two authorial sets is almost complete, with just two of the Diderot sections located in the outer fringes of the Raynal set. Since the word variables underlying this plot were the 100 most frequent words of the whole text, this is a convincing stylistic division, one that suggests a strong distinction in terms of authorship signal between the two sets.
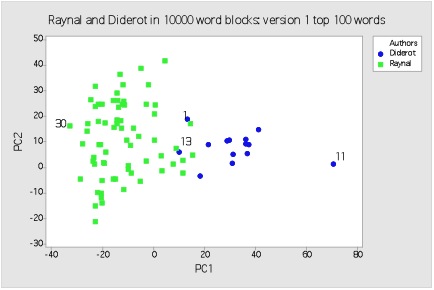
In order to account for the size discrepancy between the two corpora, we ran another PCA test but this time we increased the number of Diderot sections by segmenting his text into 5,000 word blocks and running these against the previous Raynal 10,000-word sections. This plot is shown below:
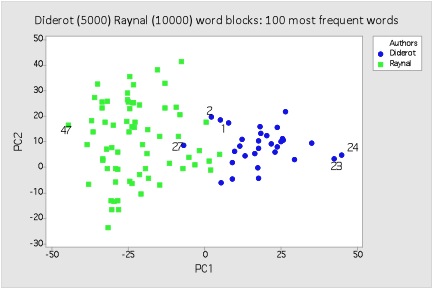
Principal component analysis on 5,000 word blocks (Diderot) and Raynal, using 100 most frequent words
Here we see the same sort of authorial/stylistic separation as we saw above, but this time (with the Diderot sections halved in size) the distinction is even stronger, as there is only one section located within the Raynal set of entries, indicating an even greater likelihood that the sections marked in pencil were written by a different author than the rest of the 1780 edition.
These are obviously very rudimentary experiments, but they nonetheless indicate several promising future avenues of exploration. Moving forward, we intend to apply a full suite of computational and stylistic approaches to the 1780 edition and its predecessors, including sequence alignment tools developed by ARTFL, text collation software, and the MEDITE system developed by the labex OBVIL at the Sorbonne for computational genetic criticism. All of these approaches will allow us to explore the textual evolution of the Histoire from 1770 to 1780 in an unprecedented manner, as well as its relationship to other Enlightenment texts and text collections such as Electronic Enlightenment, TOUT Voltaire, and the Encyclopédie.
*I would especially like to thank Alexis Antonia and the Centre for Literary and Linguistic Computing at Newcastle for their generous help with the above stylistic analyses.
[1] See Michèle Duchet, Diderot et l’Histoire des deux Indes ou l’écriture fragmentaire, Paris, Nizet, 1978, p. 22.
[2] Herbert Dieckmann, Inventaire du fonds Vandeul et inédits de Diderot, Genève, Droz, 1951.